

Written by Mo Kahn on
July 1, 2026






Multimodal AI is a type of artificial intelligence that can understand and process information from multiple sources at once, like text, images, and sound, similar to how humans do. It's already a real market category, with one industry estimate valuing the global multimodal AI market at USD 1.6 billion in 2024 and projecting about USD 27 billion by 2034.
You're probably already feeling the gap this solves. You type a prompt, get an image that's close, then wish you could also upload a reference photo, describe the mood you want, maybe add voice notes, and have the tool understand all of it together.
That's the big idea behind multimodal AI. It doesn't treat creativity as text alone. It starts to work more like a collaborator that can read your words, look at your references, and connect the pieces into one response. For artists, content creators, indie authors, side hustlers, and social media managers, that changes what AI can do in a daily workflow.
A lot of older AI tools felt like working with someone who could only read notes slid under a door. If you typed a strong prompt, they could respond. But if you wanted to show a selfie, point to a color palette, and say “make this feel like a dreamy fantasy poster,” the system often couldn't combine those signals well.
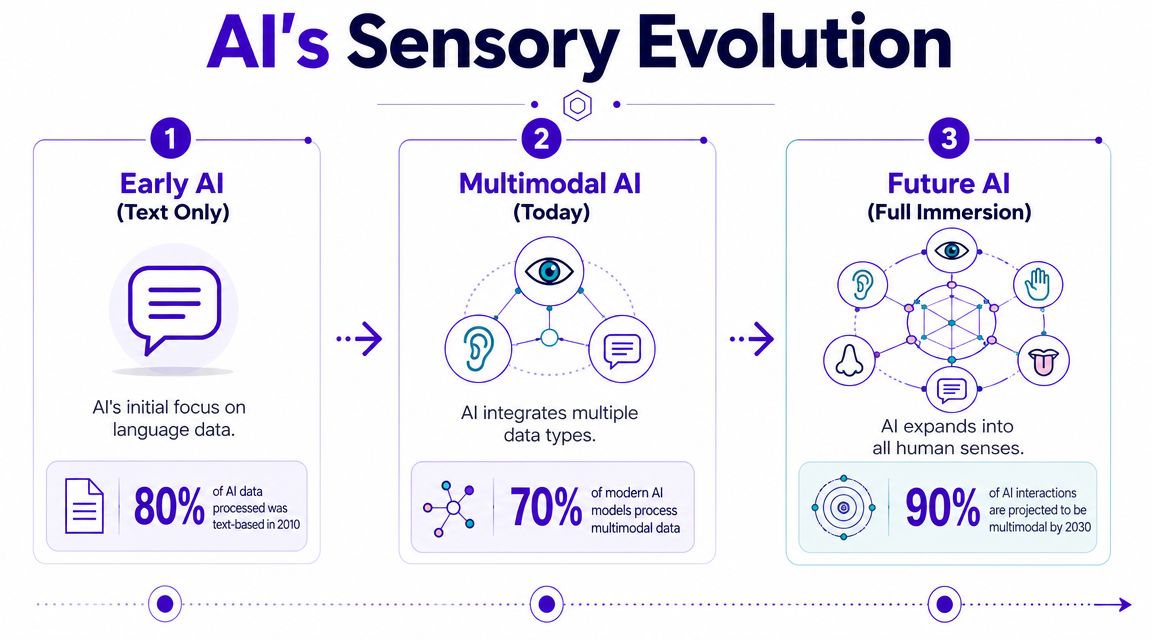
That's why what is multimodal AI matters to creators. It marks a shift from single-input systems toward tools that can work across text, images, audio, and video instead of treating each format as a separate world.
Creators rarely work in one format at a time. A TikTok concept might begin as a caption idea, turn into a reference board, become a voiceover, then end as a short video. A book cover might start with character notes, then mood images, then typography experiments.
Multimodal AI fits that reality better than older tools because it can handle richer context.
If you want to streamline video production with TTS, multimodal thinking starts to become effective. You're no longer dealing with isolated tasks. You're combining media types into one creative system.
Practical rule: The more your idea depends on relationships between words, visuals, and sound, the more likely multimodal AI will feel useful rather than gimmicky.
The commercial side reflects that shift too. One industry estimate values the global multimodal AI market at USD 1.6 billion in 2024 and projects it will reach about USD 27 billion by 2034, implying a 32.7% CAGR according to multimodal AI market analysis from Global Market Insights.
If you're already working with AI visuals, it helps to understand the image side first, especially in guides like what an AI image is. Multimodal AI builds on that foundation, then adds more senses to the conversation.
The simplest way to understand multimodal AI is to compare it with your own perception. When you meet a dog, you don't process only one signal. You see its shape, hear the bark, maybe read the name on a tag, and your brain blends those cues into one understanding.
A unimodal AI system works more like a single-sense specialist. It may only read text, or only classify images. A multimodal system can connect several kinds of input and reason across them.
Readers often get tripped up here. Multimodal does not solely mean “the app accepts uploads.” Plenty of tools let you attach an image and paste text, but they don't necessarily understand the relationship between them.
A multimodal system does something deeper. It can look at a photo, interpret written or spoken instructions about that photo, and generate a response that reflects both inputs together.
That shift became a defining milestone in the field. Major research and industry descriptions frame multimodal AI around models that jointly process text, images, audio, and video, which is what moved AI from narrow specialization toward systems that more closely resemble human perception, as explained in TileDB's guide to multimodal AI.
| Type | What it handles | Where it feels limited |
|---|---|---|
| Unimodal AI | One data type at a time | It can miss context that lives in another format |
| Multimodal AI | Multiple data types together | It's more complex, but can produce richer responses |
For a creator, that difference is practical.
Multimodal AI starts to feel useful when the relationship between inputs matters more than any single input alone.
Creative direction is usually layered. You might want “this face,” “that painterly mood,” “this caption tone,” and “that soundtrack energy.” Human collaborators understand those bundles naturally. Multimodal AI tries to do something similar in software.
That's why it's showing up across fields like healthcare diagnostics, autonomous vehicles, content moderation, customer service, and robotics in the broader market. For creators, the takeaway is simpler. AI is getting better at context, and context is where style lives.
Under the hood, multimodal AI is less magic than choreography. Think of it as a small team of translators working behind the curtain.
One translator understands text. Another understands images. Another handles audio. Each specialist takes a different kind of raw input and turns it into a form the system can compare and combine.
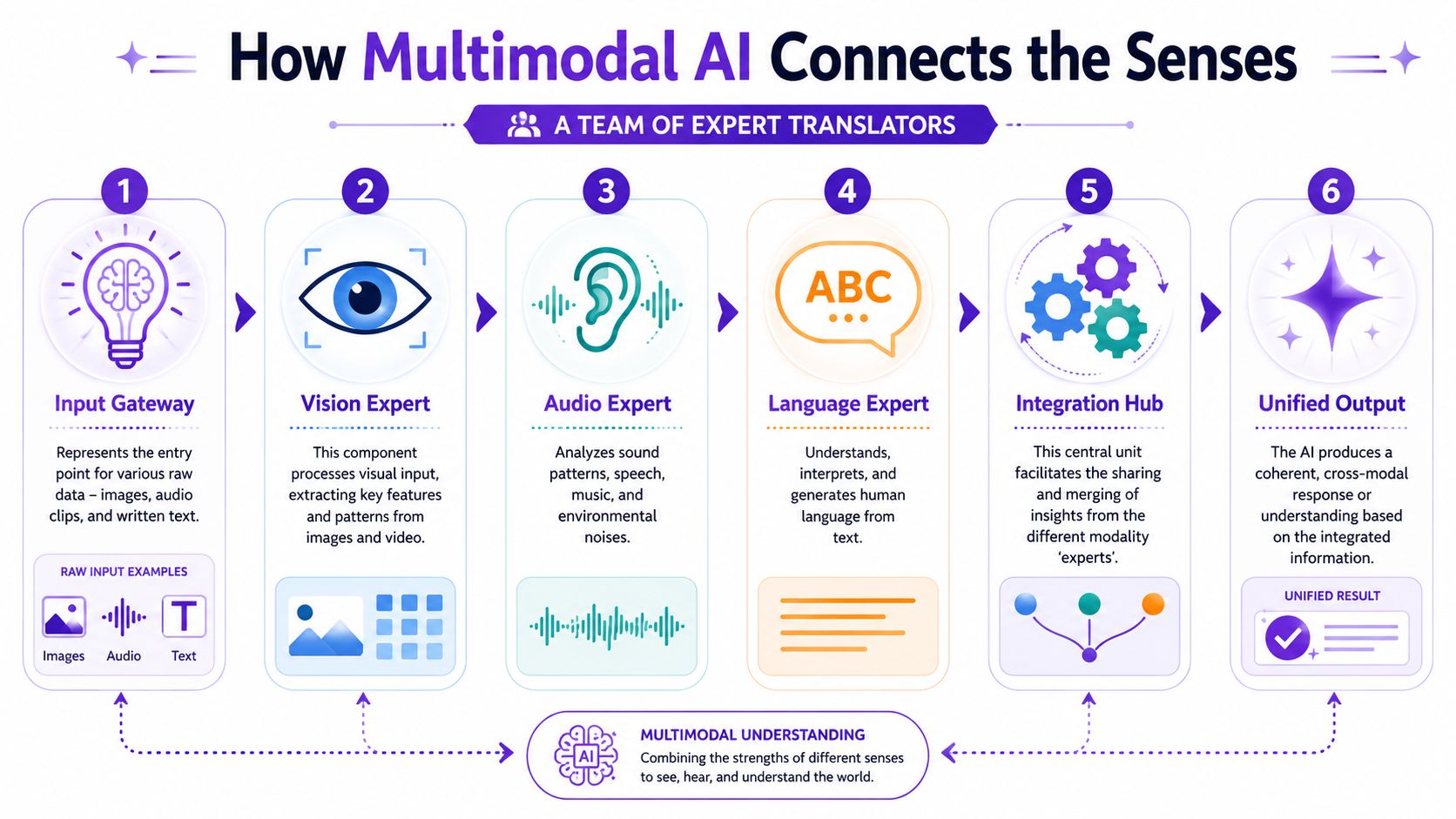
A common multimodal architecture includes an input module, a fusion module, and an output module. In more technical terms, these systems are usually built from modality-specific encoders plus a fusion layer that maps text, images, audio, or video into a shared embedding space, as described in McKinsey's explainer on multimodal AI.
Here's the plain-English version:
Input
Different encoders handle different media. Text gets tokenized. Images get resized and encoded. Audio is often transformed into features the model can interpret.
Fusion
This is the essential middle step. The system maps those different inputs into a shared space so it can compare meaning across formats.
Output
A downstream model produces the answer. That answer could be text, an image, instructions, a classification, or another generated result.
Without fusion, multimodal AI would just be a pile of separate specialists. The fusion layer is what lets the system connect your prompt to your image instead of treating them as unrelated files.
That's what enables cross-modal reasoning. A model can use an image and a text prompt together to answer a question or generate a response that reflects both.
Think of the fusion layer as the meeting table where every specialist brings notes in the same language.
This shared-space idea also explains why the technology can support flexible outputs. Once different modalities are embedded into the same high-dimensional representation, the model can support any-to-any generation, meaning it can take in one or more modalities and produce another modality as output, according to Milvus on multimodal computational requirements.
If you upload a portrait and add “turn this into a neon cyberpunk poster,” the system isn't just stacking one instruction on top of one file. It's trying to align the visual features of the portrait with the semantic meaning of the prompt before generating the result.
That's why some outputs feel uncannily on-brief, while others drift. The model has to align multiple signals correctly.
If you want a broader grounding in the ecosystem around these systems, generative AI models explained is a useful companion read. Generative models create the output. Multimodal design helps them understand a wider mix of inputs before they do.
The fastest way to understand multimodal AI is to use it for something you already care about. For creators, that usually means identity, style, speed, or storytelling.

This is one of the clearest creator use cases. You start with an image of yourself, then add text that directs the transformation.
A prompt like “turn this portrait into a moonlit elven ranger with silver armor and painterly lighting” gives the model two things at once: identity cues from the photo and style cues from language. The result can work as an avatar, profile refresh, poster concept, or fandom art.
For this kind of workflow, tools like starryai text to image are relevant because they support prompt-based image creation and can fit creators who want visual output without a technical setup.
Sometimes the goal isn't “make me look different.” It's “make this idea look more like that aesthetic.”
That might mean uploading a mood image and writing a prompt that specifies tone, palette, or genre. A creator selling prints on Etsy could use this to test directions for cottagecore, retro sci-fi, or dark academia collections. An indie author could use the same pattern for character concepts or cover exploration.
If you're in publishing, this guide to selecting AI generators for self-publishers is useful because it frames tool choice around actual cover and concept workflows rather than abstract AI hype.
Multimodal AI doesn't only generate. It can also interpret.
You can feed in an image and ask for:
That's helpful when you're stuck on naming, posting, or refining an idea you can see but haven't articulated yet.
A short demo makes this more concrete:
For short-form video creators, the interesting leap is combining script, visuals, and voice. A concept can start as a written hook, become generated imagery, then pick up narration or sound design.
That doesn't mean every creator needs a full production stack. It means the wall between “writing,” “design,” and “editing” is getting thinner. The same core idea can now move more fluidly across formats, which is why multimodal AI feels especially natural for TikTok, reels, trailers, and visual storytelling.
A good creative prompt no longer has to carry the entire job by itself. Reference media can now share the load.
Multimodal AI opens new creative doors, but it also raises the cost of getting things right. These systems are more demanding than single-input models because they have to process several streams of information and align them coherently.
Compared with unimodal systems, multimodal models require substantially more compute and memory because they must process multiple encoders and maintain larger architectures. That increases latency and raises training and inference demand, as noted in the earlier linked Milvus reference.
When a system can combine image, text, audio, and video, it can also be used to make misleading content more convincing. That includes fake visuals, manipulated voice content, or mixed-media posts designed to look authentic.
Bias is another concern. If the training material contains skewed representations, the model can carry those patterns across multiple formats at once rather than in just one channel.
A grounded way to use multimodal AI is simple:
Creators don't need to fear the technology. They do need to use it with judgment.
No. Generative AI describes systems that create outputs such as images, text, audio, or video. Multimodal AI describes systems that can understand or work across multiple kinds of input. Some tools are both. Some are only one.
A text-to-image app may be generative. A system that analyzes an image, reads your prompt, and then generates a result is both generative and multimodal.
Yes. You don't need to build models or understand machine learning math to start. Most beginners can learn the concept by trying simple workflows such as uploading a photo, adding a prompt, and comparing outputs.
Start with small experiments:
It reduces the gap between the idea in your head and the materials you already have. Instead of forcing everything into text, you can combine references, language, and sometimes sound or motion.
That's especially useful for creators who think visually first, or who build across platforms where a single concept needs to become a post, a thumbnail, a cover, a voiceover, or a short video.
The likely direction is more natural interaction. Creators will increasingly work with tools that can accept mixed inputs in a single flow, then return outputs that feel more context-aware.
The important shift isn't only better quality. It's better collaboration between your intent and the media you provide.
If you want to try that kind of workflow yourself, starryai is one option for turning prompts, selfies, and visual ideas into AI-generated images without needing a technical setup.